
科学“鄂”知道 科普“开放麦”|朱贵波:探寻人工智能多模态大模型的奥秘




编前语:5月30日,由科技部人才与科普司、湖北省科技厅主办、湖北广播电视台湖北之声承办的2023年全国科技活动周特色科技活动——科学“鄂”知道•专家科普“开放麦”在武汉举行。本次活动汇聚科普理论研究领域,聚焦江豚保护、人工智能、生态系统、地质地貌研究等领域知名科普专家,以深入浅出、妙趣横生的“开放麦”向全国、全网展示湖北深厚的科教实力和科普力量。
武汉人工智能研究院朱贵波研究员进行了人工智能领域前沿技术的科普分享,带领现场观众共同探寻了多模态大模型的奥秘。一起来听他的科普故事。
 探寻人工智能多模态大模型的奥秘朱贵波
探寻人工智能多模态大模型的奥秘朱贵波
不知道大家是否用过ChatGPT?ChatGPT可以和人用文字聊天对话,也可以用一段文字描述人的需求,进而生成图片。
“生成”是一种人工智能技术,ChatGPT是生成式大模型,它的答案是生成的,而不是复制粘贴拼凑的,也不是像搜索引擎那样,找到别人的链接里有相关的答案就一起提供过来。每一次发问,背后都是一次大模型的一次生成,也就是说,同一个问题,有可能生成不同的答案。它的答案有一定逻辑性,更像人和人之间的交流。
ChatGPT的成功标志着通用人工智能技术产品化的来临,成为AI技术发展分水岭。ChatGPT有很多强大的能力,连续高质量对话能力、修正纠错能力和逻辑推理能力。可以进行有问有答、摘要总结、分类、翻译等工作,ChatGPT尽管回复不一定完全正确,但是几乎都能够领会用户意图,对人类指令的意图理解能力远超预期。它可以实现几十轮连续对话。
国际领先的大模型能力越强,中国越要有自己的全国产化的大模型。我所在的团队就在干这样一件被托付的重要任务。国产大模型对我国实现AI自主化具有重要战略意义。我们全栈国产的大模型叫做“紫东太初”。从学术角度讲,“紫东太初”是多模态大模型,规模高达千亿参数。
多模态大模型有两个关键词,第一个多模态。第二个自监督。
何为多模态?ChatGPT主要是自然语言类的大模型,而我们人类在感知世界的时候经常会使用眼睛去看、耳朵去听、嘴巴去说、双手去写,人类的认知学习就是建立在对现实世界图像、声音和文字等多种模态信息基础之上,突破模态限制,所以实现图、文、音等更多模态的通用大模型是人工智能融入现实世界的必然。
何为自监督学习?这个技术是一种新型的人工智能技术,很好地用在了大模型中。简单来说,强化学习是人类教机器,机器给答案,人类根据机器的学习成果再教,这个过程中有奖有罚。专业说法是智能体与环境交互。深度学习是人类通过标注提供了标准答案。我们“紫东太初”团队从2019年开始就瞄准了人工智能多模态大模型领域进行集中攻关,围绕国产化超大规模模型训练的国家战略需求,基于全栈国产化基础软硬件平台,开拓性地提出了跨模态多任务自监督学习,实现了图像、文本、语音三模态数据间的“统一表示”与“相互生成”,自动获得实体概念以及概念之间的关联关系,形成了完整的智能表示、推理和生成能力,迈出了通用人工智能的重要一步。2021年9月“紫东太初”正式发布,我们团队发布的时候是全球首个千亿参数多模态大模型。“紫东太初”大模型通过将图像、文本、语音等不同模态数据实现跨模态的统一表征和学习,完成了从“一专一能”到“多专多能”的转变,这些都是能力提升上的跨越。
除了和聊天软件对话,大模型的能力通过什么来体现呢?虚拟数字人是一个很好的形式。这样,我要给大家介绍一位“新朋友”,她是一位数字虚拟人,名字叫做“小初”,紫东太初的初。随着紫东太初大模型能力的增长,小初的能力也在提高。小初的能力来自于背后的紫东太初大模型。也就是说大模型的能力越强,小初的能力就越强。
目前“小初”不仅能读懂图片、看懂视频、听懂声音,而且能进行中文续写、双语翻译、吟诗作赋等。背后的技术原理是通过图片、文字、语音等多种模态的关联与协同,可以有效地提升计算机的理解和生成能力。这些工作都让AI接近人类想象力。
我们的朋友“小初”带着她的基础能力触达了很多地方,比如,到了沙特博物馆,那里有多模态对话虚拟人;到了杭州,那里有文旅虚拟数字人南宋御街;到了马栏山,帮助特殊人群的手语老师。我们的大模型技术在一些更为严肃重大的场景中也有应用。比如,工业质检领域实现多模态在声音和图像之间实现瑕疵的检测以及通过多模态感知在智能网联汽车领域的应用。未来可期,而我们团队也将持续聚焦多模态大模型领域,加强关键核心技术攻关,促进各领域深度应用,推动数字经济全面发展。

记者:刘宁
编辑:胡明畅
审核:齐鸣 刘晓蕾 胡梦泉


 融媒体平台建设服务
融媒体平台建设服务 长江云新时代文明实践平台
长江云新时代文明实践平台

 大数据舆情中心
大数据舆情中心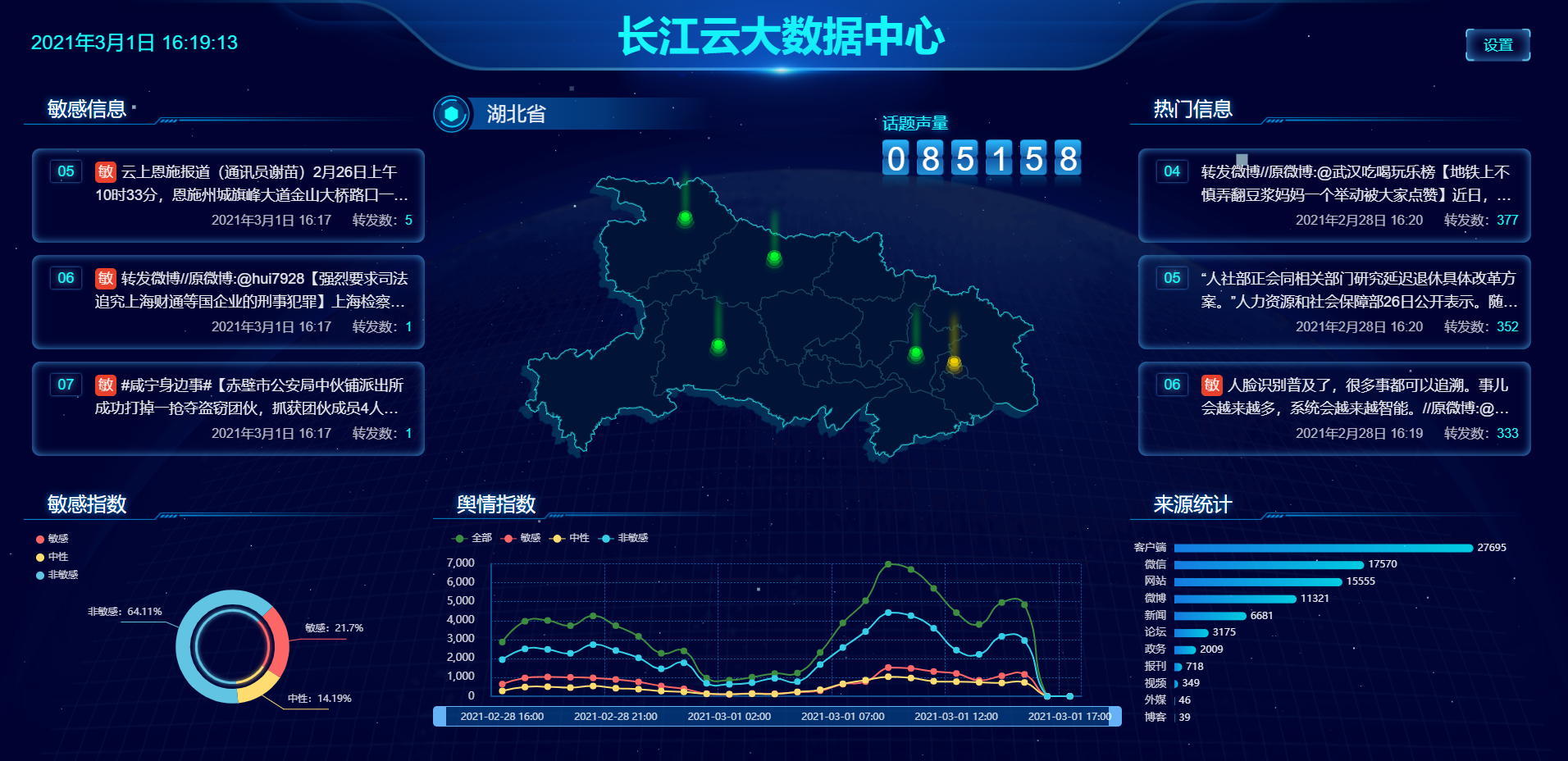


{kind=link}
{kind=link}