东风无偿开源全球规模最大的自动驾驶数据集




当AI遇上自动驾驶,大模型上车,成为全球车企决胜智能化下半场的关键。近日,东风汽车牵头发布行业内规模最大的端到端自动驾驶开源数据集,推动行业用人工智能不断优化自动驾驶技术方案。
乘坐一辆自动驾驶运营车,你是否会有避障卡顿的体验?如今这样的感受正不断优化。自动识别上下匝道、预判感知复杂环境、避障不顿挫……这是东风汽车正上路测试的端到端自动驾驶。什么是端到端自动驾驶?它是自动驾驶领域的AI模型,也是一种智能计算系统,给汽车装上AI大脑,输入原始传感器数据比如图像、雷达等,通过深度学习,让汽车自学成“老师傅”,从“看到路”到“控制车”一气呵成。

它彻底打破了传统基于规则的模块化技术方案,改变了依靠工程师手把手写代码的模式和掣肘,带动自动驾驶从“软件定义”向“AI定义”跨越。东风汽车研发总院智能化技术总工程师李红林表示,以往基于规则,主要靠我们的工程师去写规则,去设定判别条件,比如,前车和我们距离小于多少之后,我们得去减速等等这些规则,感知、决策规划、控制执行三个模块之间存在误差累计,应对复杂交通场景的时候仍有困难。

技术突围的关键,在于重塑自动驾驶的底层逻辑。端到端自动驾驶,将感知、决策、执行三个模块融为一体,用数据做训练,让机器自主学习、思考和分析,无需工程师编写冗长的代码去制定规则,避免了信息在不同模块传递时所产生的减损,精准度、效率都更高,更能实现类人化驾驶,应对更多更复杂的驾驶场景。其关键在于,用数据训练大模型,以海量数据打造丰富的“虚拟训练世界”。

新技术意味着增加投入。目前,国内不少车企明确了端到端大模型路线,吉利、长安等车企,蔚来、小鹏、理想等新势力车企,以及百度、华为等科技大厂均在布局大模型,但端到端大规模量产上车还需一段时间,这背后,数据短缺的挑战尤为突出——我国自动驾驶高质量数据体量不足、行业开源的数据集非常有限、各家车企的数据就像一个个“孤岛”。李红林介绍,数据采集、标注、质检、脱敏等环节耗时耗力,比如,提取20秒的边缘场景片段,数据采集与处理需要1至2个小时。同时,端到端自动驾驶研发,对一个企业的技术和AI人才聚集的要求非常高。

如何推动行业技术跃迁?数据是关键驱动力。过去两年,依托提前布局和持续投入,东风汽车积累了大量真实驾驶数据。近日,东风汽车牵头发布了行业最大规模的端到端自动驾驶开源数据集,涵盖125万组数据、超6000个场景片段,规模是当前行业最大开源数据的4倍。庞大的数据集,犹如一本“超级教科书”,成为端到端自动驾驶系统学习的超级教材。每个场景都有详细的“标注”,就像课本里的重点笔记,告诉自动驾驶系统“这时候应该这么做”。比如“下雨天怎么避开积水”“晚上会车时保持怎样的距离”“遇到突然窜出的行人该怎么反应”等等。但仅仅是开放的这批数据集,处理成本接近4000万。
为何大规模开放?李红林表示,企业尝过“缺数据”的苦。2022年开始探索这条路线的时候,就深刻地体会到数据缺乏的时候,整个模型的性能的上限是非常低的。作为央企,东风汽车使命在肩,有责任去助力高校、中小型企业更快地走上这条新路径。有了这个开源数据集,大家基于同样的高质量数据做研究,就能推动算法迭代、自动驾驶技术更快进步。

眼下,以这本超级教科书为依托,东风汽车还与国内高校、产业链企业加强产业协同,共研下一代端到端大模型,并加速推进端到端自动驾驶系统量产。东风汽车研发总院人工智能实验室执行负责人黄睿表示,目前,以课题的形式与高校合作,华中科技大学、武汉理工大学等,更多聚焦算法和模型的迭代优化,东风汽车提供更真实的数据来源、丰富的应用场景,预计今年底,将量产端到端自动驾驶大模型,搭载应用在东风奕派008等车型,加速达成真正“类人”的智驾能力。
(长江云新闻记者 杜瑞雪 张龙 通讯员 顾盛炜 武汉经开区融媒体 编审 徐瑗 尚大原)


 社会保障
社会保障 交通出行
交通出行 公积金
公积金 公安服务
公安服务 职业资格
职业资格 医疗健康
医疗健康 市场监管
市场监管 法律服务
法律服务
 融媒体平台建设服务
融媒体平台建设服务 长江云 • 新时代文明实践平台
长江云 • 新时代文明实践平台

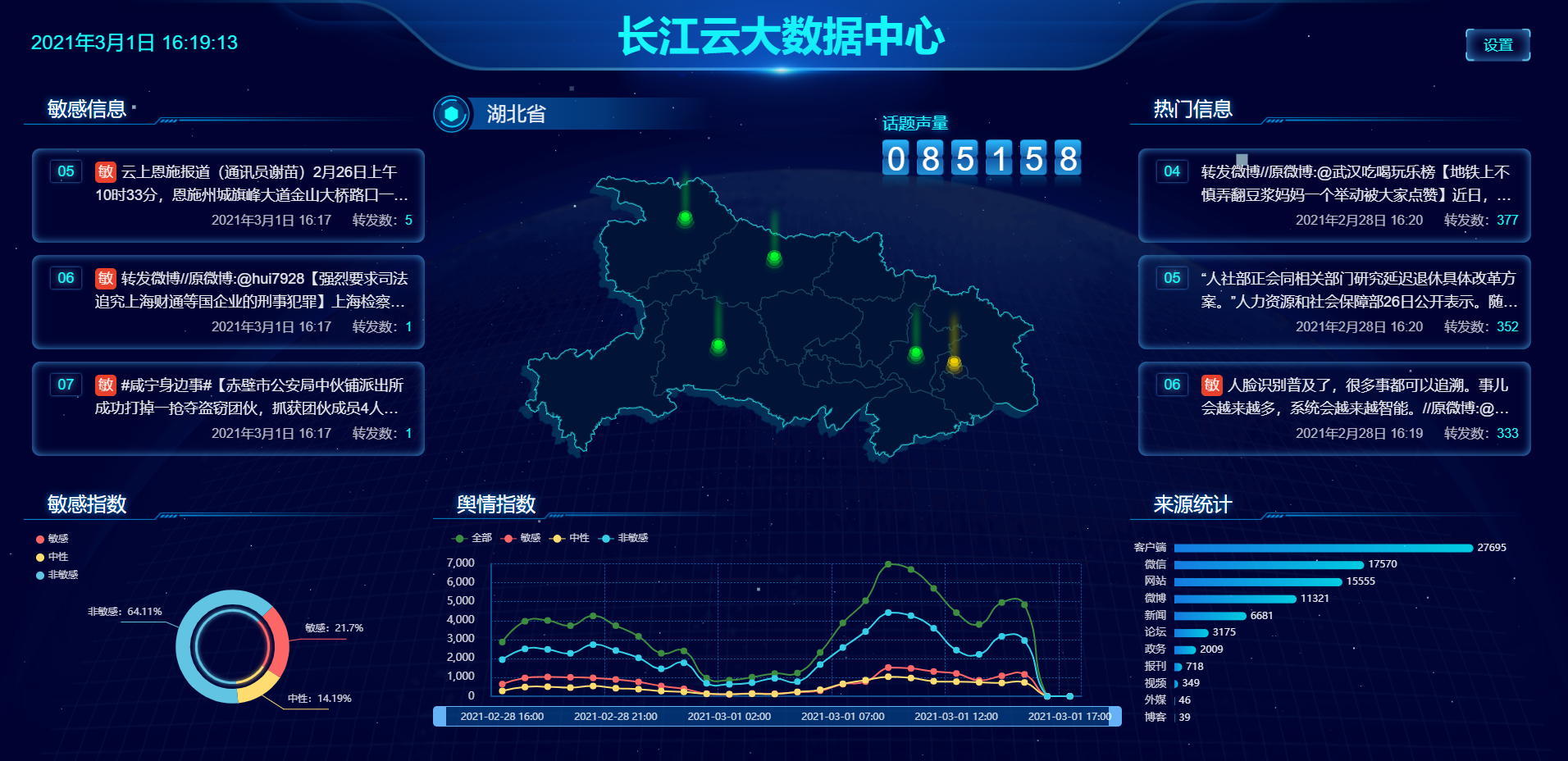
 大数据舆情中心
大数据舆情中心